15.3 Transformação de dados com dbt
Contents
15.3 Transformação de dados com dbt#
Nesta seção vamos apresentar como fazer a modelagem de um DW na prática usando o dbt. Para tanto, nós precisamos primeiro realizar a carga dos dados brutos em nosso DW (que fizemos na seção anterior). Com os dados já inseridos no DW, vamos criar uma séries de modelos para materializar o modelo conceitual do DW que criamos anteriormente.
Antes de começar a parte técnica, é bom lembrar que o objetivo de um DW é gerar resultado para a empresa e não criar um sistema que, embora possa ser tecnicamente bem feito, não tenha uma visão de negócio. Deste modo, a forma como criamos os marts e suas tabelas fato e dimensões deve ser sempre pensado nos problemas prioritários na tomada de decisão e na utilização pelo usuário final. Um erro comum de projetos de DW é pensar mais nos modelos de dados das aplicações-fonte e menos no modelo de negócios do usuário final. Se for difícil saber a priori como será essa utilização, podemos recorrer a instrumentos já usados na tomada de decisão como relatórios, planilhas, etc. para ter uma ideia de que tipo de relações e atributos são mais relevantes para o cliente.
Atualmente o dbt possui uma versão SaaS chamada dbt cloud além da versão open-source. A versão SaaS possui um custo de aprendizagem menor para quem tem menos contato com programação, mas neste curso vamos utilizar a versão open-source. No geral, ambos são muito similares e você utilizar a versão cloud de forma equivalente se desejar.
Dica!
Para lembrar os comandos do dbt facilmente utilize essa cheatsheet
Começando um projeto#
Nesta subseção vamos aprender como iniciar um projeto dbt. Vamos lá?
Instruções de exemplo#
A forma mais fácil de acompanhar esta seção é clonar o projeto de exemplo disponível neste repositório. Siga as instruções no README do repositório para instalar e configurar o dbt corretamente no seu computador.
Criando um projeto dbt#
O primeiro passo de um projeto dbt é a criação da pasta onde estão estruturados os arquivos do projeto. A forma mais fácil de criar essa pasta é através do comando dbt init. Você também vai precisar criar um repositório git na pasta para controlar o versionamento do projeto. Todo projeto é iniciado com um arquivo dbt_project.yml padrão, neste arquivo são configurados diversas opções do projeto incluindo a conexão com o data warehouse, tipo de materialização das tabelas, entre outros.
Atenção!
Se você clonou o repositório de exemplo, as etapas dessa subseção já terão sido feitas para você.
name: 'northwind'
version: '1.0.0'
config-version: 2
profile: 'northwind'
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
target-path: "target" # directory which will store compiled SQL files
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
models:
northwind:
staging:
+materialized: table
Exemplo de dbt_project.yml
O dbt init também cria uma estrutura de pastas e arquivos padrão para todo projeto dbt:
.
├── analyses
├── dbt_packages
├── dbt_project.yml
├── logs
├── macros
├── models
├── README.md
├── seeds
├── snapshots
├── target
└── tests
9 directories, 2 files
Configurando a conexão com o Data Warehouse#
A conexão com o data warehouse é configurada por padrão no arquivo profiles.yml que fica armazenado no caminho ~/.dbt/profiles.yml (LINUX). As permissões do arquivo devem ser restritas ao usuário pois possuem credenciais de acesso aos dados que não devem ser compartilhadas.
A opção target permite alterar entre um ambiente de desenvolvimento e produção de forma simples. O target de produção deve se chamar “prod” pois é usado em outros APIs do dbt. Durante o desenvolvimento, esse target não deve ser usado mas sim um target “dev” ou equivalente.
Atualmente o dbt possui drivers para os principais data warehouses na nuvem e alguns bancos de dados tradicionais, cada driver possui configurações específicas que podem ser consultadas aqui.
northwind:
outputs:
dev:
dataset: northwind
job_execution_timeout_seconds: 300
job_retries: 1
keyfile: path/to/keyfile.json
location: US
method: service-account
priority: interactive
project: <project_id>
threads: 1
type: bigquery
Exemplo de dbt Profile
Para verificar se tudo está bem configurado, podemos usar o comando dbt debug no terminal. Em caso de sucesso, devemos ter um output como esse:
dbt debug
(...)
Connection test: [OK connection ok]
All checks passed!
Salvando nossas alterações#
É importante salvar frequentemente nossas alterações no projeto. Por ser um projeto de código (lembrem-se do princípio de data as code), as alterações são salvas como commits em um sistema de controle de versão git.
Importante!
Se você não tem contato com git, recomendamos revisar o capítulo sobre Git ou buscar outros conteúdos online.
git init
git branch -M main
git add .
git commit -m "Criei um projeto dbt"
git remote add origin https://github.com/USERNAME/dbt-northwind.git
git push -u origin main
Criando nossos primeiros modelos#
Agora que temos o ambiente configurado podemos trabalhar na construção dos modelos dbt. Cada modelo se tornará um objeto no data warehouse seguindo nosso planejamento do ELT.
Começando uma nova branch#
Antes de iniciar nossa construção dos modelos, é recomendável criar uma nova branch de trabalho para salvarmos nossas alterações. Para isso podemos executar no terminal:
git checkout -b novos_modelos_dbt
Criando nossas primeiras fontes de dados#
Agora que configuramos nossa conexão com o data warehouse, precisamos criar nossas primeiras fontes de dados. Essas fontes são definidas no arquivo sources.yml, onde é possível descrever quais os bancos de dados, schemas e tabelas que queremos deixar disponíveis no dbt.
Atenção!
Nesta seção é esperado que os dados brutos da Northwind já estejam disponíveis no Data Warehouse através de um processo de ingestão como visto aqui ou através de um dbt seed como sugerido aqui.
Depois de definidas as fontes, elas podem ser chamadas nos modelos através da sintaxe:
select *
from {{source('nome_fonte', 'nome_tabela')}}
Não é necessário mapear todas as tabelas do data warehouse de uma vez, mas podemos adicionar de forma incremental o que for necessário para os modelos. O uso do arquivo de sources permite criar a linhagem dos dados através da função { source('nome_da_fonte',’nome_da_tabela’)}} e também permite documentar e escrever testes sobre as fontes de dados.
version: 2
sources:
- name: northwind # aqui você deve substituir pelo nome do dataset criado pela ferramenta de ingestão no bigquery
schema:
description: Essa é a fonte de dados do nosso ERP
tables:
- name: products
description: Essa é a tabela de produtos do ERP.
- name: employees
description: Essa é a tabela de funcionários do ERP.
- name: customers
description: Essa é a tabela de clientes do ERP. O dono desse dado é a equipe comercial.
Uma boa prática é incluir o arquivo sources.yml no diretório staging onde fazemos as primeiras transformações sobre os dados originais. Em geral, cada source deve ser referenciada apenas em um modelo, facilitando a consistência na modelagem como iremos discutir na próxima seção.
Criando nossos primeiros modelos#
Um modelo em dbt é um arquivo .sql que tem como input uma tabela fonte do banco de dados ou um outro modelo do dbt. Por padrão, o dbt irá criar um objeto no banco de dados com o mesmo nome do arquivo e com o tipo de materialização escolhida (tabela, visualização, etc). Ao utilizar corretamente a interface do dbt, conseguimos garantir a linhagem dos dados, isto é, a ordem correta com que cada script sql deve ser executada no banco de dados. Embora seja possível escrever um modelo .sql que referencia diretamente uma tabela do banco de dados, essa prática deve ser evitada. As duas interfaces principais de um modelo são as funções {{ source('nome_da_fonte',’nome_da_tabela’)}} e {{ ref(‘nome_do_modelo’) }} A primeira indica ao dbt que aquele modelo utiliza dados da tabela fonte do banco de dados que não depende de outros modelos, e a segunda indica que a fonte dos dados é um outro modelo que pode ou não existir no banco de dados inicialmente e deve ser processado na sequência correta.

Fig. 54 Exemplo de dependências no dbt#
Nos modelos staging (abreviados com o prefixo stg) importamos as sources e aplicamos transformações simples para “limpar” os dados da origem e adequar a nosso modelo de dados:
Renomear colunas
Alterar tipos de dados
Criar novas colunas dependentes (concatenar, separar, etc)
Em nosso primeiro modelo vamos ler a tabela customers da fonte northwind e criar uma versão staging em nosso DW. Neste momento é interessante verificar as colunas e tipos que foram criados durante a ingestão através de uma ferramenta de consulta SQL. A partir do data model, podemos copiar e colar as colunas em uma CTE em nosso modelo e realizar as transformações necessárias.
Atenção.
Você pode notar que os modelos dim_products e stg_products já estão disponíveis no repositório de exemplo. Use-os como referência para construir os demais modelos.
with
source_data as (
select
country
, city
, fax
, postal_code
, address
, region
, customer_id
, contact_name
, phone
, company_name
, contact_title
from {{source('northwind','customers')}}
)
select *
from source_data
Ao explorar melhor as chaves e o modelo conceitual do DW, identificamos as seguintes relações no nosso mart de orders:
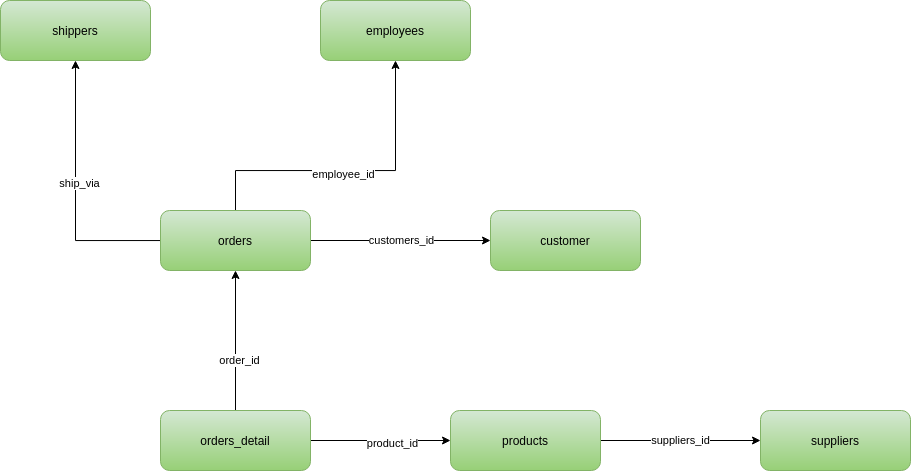
Fig. 55 Modelo conceitual da Northwind#
Para facilitar nosso entendimento, também criamos um modelo conceitual com o mapeamento das relações. Na prática, podemos fazer isso diretamente no código e depois deixar o próprio dbt gerar esse diagrama para nós:
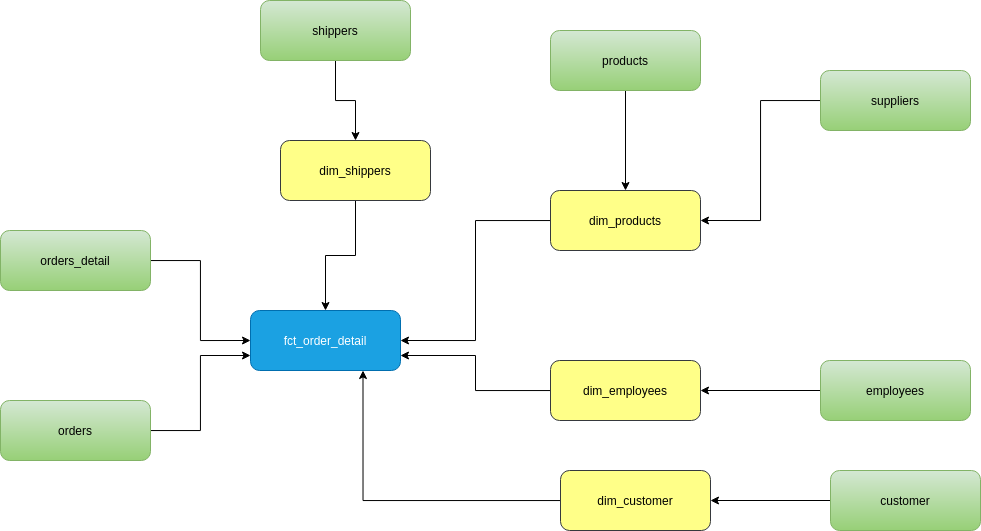
Fig. 56 Modelo dimensional da Northwind#
A partir deste diagrama podemos definir uma sequência de tarefas que precisamos para modelar nosso data mart antes de rodar o pipeline:
Incluir todas as tabelas necessárias no arquivo sources.yml
Criar os modelos staging necessários
Criar as tabelas dimensão e chaves surrogates
Criar a tabela fato
A estrutura final do nosso projeto ficaria mais ou menos assim:
├── marts
│ ├── dim_customers.sql
│ ├── dim_customers.yml
│ ├── dim_employees.sql
│ ├── dim_products.sql
│ ├── dim_products.yml
│ ├── dim_shippers.sql
│ ├── dim_suppliers.sql
│ ├── fct_order_detail.sql
│ └── fct_order_detail.yml
└── staging
├── sources.yml
├── stg_customers.sql
├── stg_employees.sql
├── stg_order_detail.sql
├── stg_orders.sql
├── stg_products.sql
├── stg_shippers.sql
└── stg_suppliers.sql
Vamos omitir as etapas 1 e 2 e partir diretamente para a etapa 3: Criar as tabelas dimensão e chaves surrogates. Vamos iniciar pela tabela de clientes (customers) e criar uma chave surrogate auto-incremental a partir da chave de negócio customer_id:
Importante!
As chaves auto-incrementais são muito utilizadas em bancos de dados e de fácil entendimento pelos consumidores dos dados. No entanto, em data warehouses modernos elas podem ser perigosas. Por quê?
with
staging as (
select *
from {{ref('stg_customers')}}
)
, transformed as (
select
row_number() over (order by customer_id) as customer_sk -- auto-incremental surrogate key
, customer_id
, country
, city
, fax
, postal_code
, address
, region
, contact_name
, phone
, company_name
, contact_title
from staging
)
select * from transformed
Depois de criadas as tabelas dimensão, mudamos nossa atenção para a tabela fato. Iniciamos pela tabela de capa do pedido (orders) e suas dimensões dim_shippers, dim_customers e dim_employees. A ideia é criar uma tabela fato apenas com as chaves estrangeiras porém logo vemos que algumas colunas da tabela de pedidos não são medidas mas crescem proporcionalmente à tabela fato (informações de entrega, Código do Pedido, etc). Deste modo, resolvemos deixar essas informações na tabela fato como dimensões degeneradas.
with customers as (
select
customer_sk
, customer_id
FROM {{ref('dim_customers')}}
),
employees as (
select
employee_sk
, employee_id
FROM {{ref('dim_employees')}}
),
suppliers as (
select
supplier_sk
, supplier_id
FROM {{ref('dim_suppliers')}}
),
shippers as (
select
shipper_sk
, shipper_id
FROM {{ref('dim_shippers')}}
),
products as (
select
product_sk
, product_id
FROM {{ref('dim_products')}}
),
orders_with_sk as (
select
orders.order_id
, employees.employee_sk as employee_fk
, customers.customer_sk as customer_fk
, shippers.shipper_sk as shipper_fk
, orders.order_date
, orders.ship_region
, orders.shipped_date
, orders.ship_country
, orders.ship_name
, orders.ship_postal_code
, orders.ship_city
, orders.freight
, orders.ship_address
, orders.required_date
from {{ref('stg_orders')}} orders
LEFT JOIN employees employees ON orders.employee_id = employees.employee_id
LEFT JOIN customers customers ON orders.customer_id = customers.customer_id
LEFT JOIN shippers shippers ON orders.shipper_id = shippers.shipper_sk
)
select * from orders_with_sk
Ocorre que não queremos apenas a capa dos pedidos mas também o detalhamento desses pedidos na tabela fato, ou seja, queremos que o grão da tabela seja cada item do pedido de modo que possamos somar um total ou média de pedidos por produto/cliente sem recorrer a outras operações de JOIN. Como já vimos no capítulo anterior, a melhor opção é juntar a capa do pedido (orders) e o detalhe do pedido (order_details) na mesma tabela fato, ainda que essa arquitetura não seja tão eficiente em termos de armazenamento:
(...)
, final as (
select
order_dtl.order_id
, orders.employee_fk
, orders.customer_fk
, orders.shipper_fk
, orders.order_date
, orders.ship_region
, orders.shipped_date
, orders.ship_country
, orders.ship_name
, orders.ship_postal_code
, orders.ship_city
, orders.freight
, orders.ship_address
, orders.required_date
, order_dtl.product_fk
, order_dtl.discount
, order_dtl.unit_price
, order_dtl.quantity
from orders_with_sk orders
left join orders_detail_with_sk order_dtl on orders.order_id = order_dtl.order_id
)
select * from final
Rodando o pipeline#
Falamos sobre como criar os modelos .sql do dbt mas não como eles são materializados de fato, ou seja, se tornam tabelas, visualizações etc. Este processo é realizado através do comando dbt run ou dbt build, que processa as dependências entre os modelos geradas a partir das macros {{ ref() }} e {{ source()}} e executa cada script na sua sequência correta:
Para saber mais.
Leia a documentação oficial do dbt e entenda a diferença entre o dbt run e dbt build.
$ dbt run
00:01:47 Running with dbt=1.3.0
00:01:47 Found 2 models, 5 tests, 0 snapshots, 0 analyses, 319 macros, 0 operations, 14 seed files, 7 sources, 0 exposures, 0 metrics
00:01:47
00:01:48 Concurrency: 1 threads (target='dev')
00:01:48
00:01:48 1 of 2 START sql table model northwind.stg_products ............................ [RUN]
00:01:51 1 of 2 OK created sql table model northwind.stg_products ....................... [CREATE TABLE (77.0 rows, 7.5 KB processed) in 3.34s]
00:01:51 2 of 2 START sql view model northwind.dim_products ............................. [RUN]
00:01:53 2 of 2 OK created sql view model northwind.dim_products ........................ [CREATE VIEW (0 processed) in 1.20s]
00:01:53
00:01:53 Finished running 1 table model, 1 view model in 0 hours 0 minutes and 5.38 seconds (5.38s).
00:01:53
00:01:53 Completed successfully
00:01:53
00:01:53 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2
Podemos notar no output do dbt run que o dbt nos informa o tipo de materialização de cada modelo. Mas como configuramos isso? Há duas formas: através de uma configuração em cada modelo ou de forma mais geral no dbt_project. No primeiro exemplo abaixo, podemos dizer para o dbt materializar o modelo fct_order_detail como tabela no banco de dados, aumentando a performance em relação à visualização (view). No segundo caso, resolvemos que as tabelas staging não são necessárias em nosso DW mas apenas no processo de transformação e por isso definimos que todos os modelos na pasta models/staging não serão materializados (ephemeral). Quando os dois casos estiverem presentes para o mesmo modelo, a configuração dada no modelo leva prioridade sobre a presente no projeto. Em geral, devemos evitar configurar materializações nos modelos e utilizar as opções do dbt_project.
{{config (materialized='table')}}
with customers (
(...)
)
(...)
Exemplo de configuração de materialização no modelo do dbt
models:
northwind:
staging:
materialized: ephemeral
marts:
materialized: table
Exemplo de configuração de materialização no dbt_project.yaml
Em geral, tabelas são preferíveis para otimizar as consultas no BI pois possuem um desempenho melhor de leitura que uma visualização (view). Durante a etapa de desenvolvimento o uso de views geralmente é mais rápido na hora de executar o pipeline, principalmente se as tabelas forem muito grandes.
Escrevendo testes#
Garantir a integridade dos dados na transformação é parte essencial de qualquer projeto de ETL e o dbt foi pensando com as melhores práticas de engenharia de software em mente, em especial a capacidade de escrever testes sobre os dados de forma direta e consistente.
Quanto mais cedo incluirmos testes no processo de ETL, mais fácil será a validação dos modelos finais com o cliente. É por isso que recomendamos inverter o processo e escrever testes antes mesmo de escrever os modelos.
Conceitualmente, há dois tipos de testes no dbt:
testes genéricos (antigos testes de schema): são definidos em um arquivo .yaml e permitem realizar testes gerais sobre colunas da tabela, tais como: unicidade, não-nulicidade, valores dentro de uma lista pré definida, relacionamentos, entre outros. O teste falha quando há algum registro que não passa em um teste específico . Ex. há um registro duplicado em uma coluna com teste de unicidade.
testes singulares (testes de dados): são consultas sql que devem retornar 0 linhas para passarem no teste. Geralmente são testes baseados em dados validados com o cliente e de grande importância para garantir que os modelos estão gerando resultados consistentes.
De forma geral, devemos incluir ao menos um testes genérico para cada modelo na sua chave primária (surrogate ou natural). Por exemplo, para garantir que não tenhamos nenhum cliente repetido na tabela de clientes, vamos criar um arquivo dim_customers.yml e incluir dois testes para a chave sk:
version: 2
models:
- name: dim_customers
columns:
- name: customer_sk
description: The primary key of the customer
tests:
- unique
- not_null
Para entender como os testes funcionam na prática, precisamos rodar o comando dbt run no terminal. Ao fazê-lo, o dbt converte os testes em consultas SQL apropriadas e retorna o resultado (sucesso ou falha) de forma similar a um modelo:
$ dbt test
00:07:00 Running with dbt=1.3.0
00:07:00 Found 2 models, 5 tests, 0 snapshots, 0 analyses, 319 macros, 0 operations, 14 seed files, 7 sources, 0 exposures, 0 metrics
00:07:00
00:07:00 Concurrency: 1 threads (target='dev')
00:07:00
00:07:00 1 of 5 START test accepted_values_dim_products_is_discontinued__No__Yes ........ [RUN]
00:07:02 1 of 5 PASS accepted_values_dim_products_is_discontinued__No__Yes .............. [PASS in 1.86s]
00:07:02 2 of 5 START test not_null_dim_products_product_sk ............................. [RUN]
00:07:04 2 of 5 PASS not_null_dim_products_product_sk ................................... [PASS in 1.89s]
00:07:04 3 of 5 START test source_not_null_northwind_orders_order_id .................... [RUN]
00:07:06 3 of 5 PASS source_not_null_northwind_orders_order_id .......................... [PASS in 1.55s]
00:07:06 4 of 5 START test source_unique_northwind_orders_order_id ...................... [RUN]
00:07:07 4 of 5 PASS source_unique_northwind_orders_order_id ............................ [PASS in 1.78s]
00:07:07 5 of 5 START test unique_dim_products_product_sk ............................... [RUN]
00:07:09 5 of 5 PASS unique_dim_products_product_sk ..................................... [PASS in 1.97s]
00:07:09
00:07:09 Finished running 5 tests in 0 hours 0 minutes and 9.67 seconds (9.67s).
00:07:09
00:07:09 Completed successfully
00:07:09
00:07:09 Done. PASS=5 WARN=0 ERROR=0 SKIP=0 TOTAL=5
Vemos que nossa tabela dimensão clientes não possui nenhum registro repetido ou nulo na coluna customer_sk. Mas e se fizermos o mesmo teste para a coluna order_id na tabela de pedidos? o que esperamos encontrar? Lembremos que optamos por juntar na tabela fato a tabela de itens por pedido, de modo que podemos ter múltiplas linhas para cada pedido. Ao rodar um teste de unicidade para o id do pedido (order_id), esperamos que esse teste falhe e é exatamente isso que acontece. Vemos que o dbt encontrou 693 linhas repetidas quando esperávamos nenhuma:
$ dbt test
00:21:52 Running with dbt=1.3.0
00:21:53 Found 3 models, 7 tests, 0 snapshots, 0 analyses, 319 macros, 0 operations, 14 seed files, 7 sources, 0 exposures, 0 metrics
...
00:22:01 5 of 7 FAIL 693 source_unique_northwind_order_details_order_id ................. [FAIL 693 in 1.58s]
00:22:01 6 of 7 START test source_unique_northwind_orders_order_id ...................... [RUN]
00:22:03 6 of 7 PASS source_unique_northwind_orders_order_id ............................ [PASS in 1.32s]
00:22:03 7 of 7 START test unique_dim_products_product_sk ............................... [RUN]
00:22:05 7 of 7 PASS unique_dim_products_product_sk ..................................... [PASS in 2.11s]
...
00:22:05 Completed with 1 error and 0 warnings:
00:22:05
00:22:05 Failure in test source_unique_northwind_order_details_order_id (models/staging/sources.yml)
00:22:05 Got 693 results, configured to fail if != 0
00:22:05
00:22:05 compiled Code at target/compiled/northwind/models/staging/sources.yml/source_unique_northwind_order_details_order_id.sql
00:22:05
00:22:05 Done. PASS=6 WARN=0 ERROR=1 SKIP=0 TOTAL=7
É comum que durante o processo de modelagem aconteçam transformações que porventura dupliquem registros que deveriam ser únicos (um join equivocado por exemplo) ou que possivelmente existam regras de negócio que não sabíamos de antemão. Para esses casos, escrever testes de forma consistente facilita muito o trabalho de validação e desenvolvimento dos modelos com segurança. Além de unicidade e não-nulidade, outros testes de schemas comuns a serem incluídos nos modelos são:
Teste de relacionamento (relationship): os testes de relacionamento servem para garantir relacionamentos entre colunas de modelos distintos, similar ao comportamento de chaves estrangeiras no banco transacional. Geralmente é utilizado para mapear chaves de dimensões dentro das tabelas fato.
version: 2
models:
- name: fct_order_detail
columns:
- name: employee_fk
description: The foreign key to the employees dimension table
tests:
- relationships:
to: ref('dim_customers')
field: 'customer_sk'
Teste de valores aceitos (accepted_values): esse tipo de teste serve para garantir que os valores de uma coluna estejam em um intervalo pré-definido. Por exemplo, em uma coluna de status de pedido.
version: 2
models:
- name: dim_products
columns:
- name: is_discontinued
tests:
- accepted_values:
values: ['No','Yes']
Na maioria dos casos, a grande dificuldade no processo de modelagem de dados é garantir que indicadores e resultados sejam os mesmos (ou próximos) dos considerados ‘verdadeiros’ pelo cliente. Não raramente o próprio cliente não tem uma visão clara dos passos necessários, fontes de dados e regras de negócios que são aplicadas antes da geração de um indicador em um relatório ou planilha de Excel e é o trabalho do analytics engineer trabalhar de forma integrada com o cliente para extrair essas informações e aplicar no processo de modelagem. Para facilitar esse trabalho podemos utilizar os testes de dados. isto é, consultas SQL arbitrárias em cima dos modelos que garantem que nossos modelos cheguem no resultado desejado. Para evitar outros problemas como dados mutáveis, atraso no ETL etc, o ideal é sempre fixarmos um período retroativo onde temos confiança que os dados não irão se alterar.
Como exemplo, queremos validar a quantidade de itens em pedidos da nossa tabela de fatos de pedidos (fct_order_detail). Para isso, vamos fazer uma consulta nos dados originais e fixar os pedidos criados em março de 1998 como período de validação. Podemos gerar a consulta diretamente em SQL e logo obtemos uma quantidade de 4065 unidades vendidas.
Após hipoteticamente confirmarmos com a Northwind que esse número é consistente, podemos utilizar como validação em nosso teste de dados sum_quantity_march_1998.sql. Notamos que a sintaxe do teste é muito próxima de um modelo mas que devemos escrever nossa consulta final como se quiséssemos que ele “desse errado”, isto é, queremos retornar todas as linhas onde o teste não passa ao rodar o dbt test, e o sucesso no teste ocorre quando o resultado da consulta é vazio.
* If sum of quantity in March-1998 is not 4065, throws an error */
with
sum_quantity as (
SELECT
sum(quantity) as cnt
FROM {{ ref ('fct_order_detail') }}
where order_date
between '1998-03-01' and '1998-03-31'
)
select * from sum_quantity where cnt != 4065
Ao combinarmos o uso de testes genéricos e singulares desde o início do projeto, garantimos a consistência e integridade do ETL mesmo em projetos com centenas de modelos.
Documentando o modelo de dados e visualizando as dependências#
A última etapa dentro de um projeto padrão de dbt é a documentação dos modelos e transformações. Essa documentação é feita a partir dos arquivos schema.yml que já utilizamos para escrever nossos testes de schema através de campos de descrição de tabelas e colunas. Ao criarmos as descrições, elas são adicionadas com outras informações que o dbt processa de como as fontes, modelos e testes do projeto estão estruturados. No exemplo abaixo documentamos a tabela dimensão Produtos e cada uma de suas colunas, de preferência na mesma ordem que no modelo final:
version: 2
models:
- name: dim_products
description: Esta é a tabela dimensão produto da northwind. Ela contém informações sobre os produtos da empresa.
columns:
- name: product_sk
description: A chave surrogate da dimensão. Deve ser única.
tests:
- unique
- not_null
- name: product_id
description: A chave natural do produto.
- name: product_name
description: Nome do produto
- name: units_in_stock
description: Total de unidades em estoque de um determinado produto.
- name: category_id
description: A chave natural da categoria do produto.
- name: unit_price
description: O preço unitário do produto (mais recente)
- name: reorder_level
description: Ponte de re-estocage do produto
- name: supplier_id
description: A chave natural do forncedor
- name: units_on_order
description: Quantidade mínima por pedido
- name: is_discontinued
description: Binário. Se o produto foi descontinuado.
tests:
- accepted_values:
values: ['No','Yes']
Embora já seja importante para o entendimento dos modelos junto ao código, é quando utilizamos o comando dbt docs que vemos o diferencial de utilizar o dbt nesse quesito. O comando dbt docs generate gera um arquivo de documentação em formato html que conseguimos visualizar de forma interativa no navegador mesmo em projetos complexos, facilitando a colaboração e compartilhamento da modelagem. A visualização é feita através do dbt docs serve no terminal:
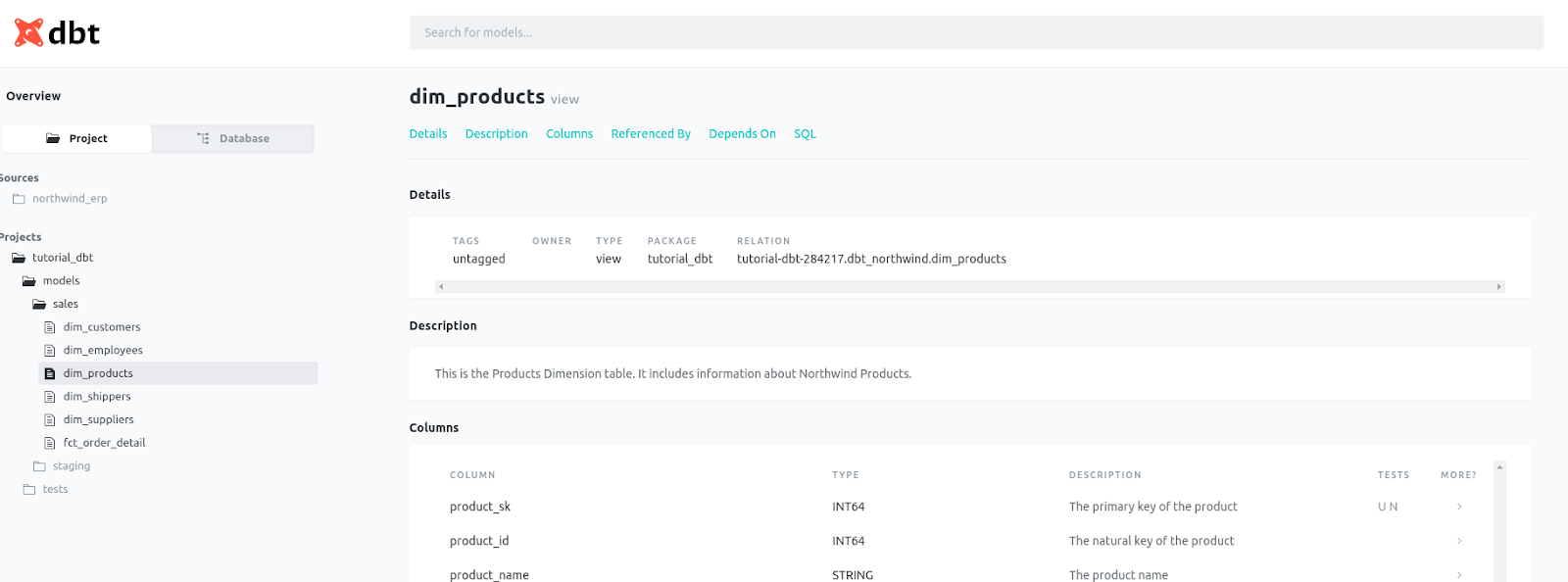
Fig. 57 Exemplo de documentação do dbt#
Além das descrições, o dbt gera uma árvore de dependências dos modelos que facilita o entendimento do ETL:
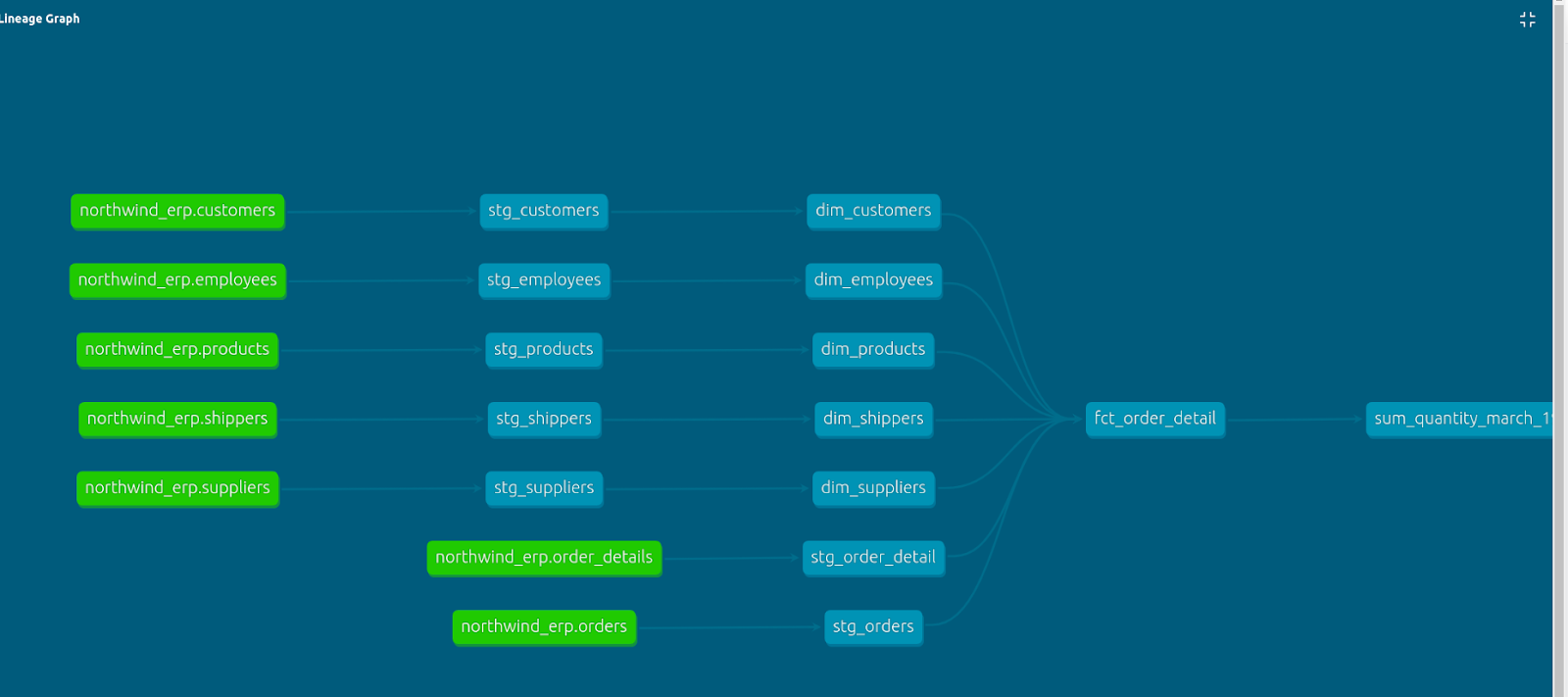
Fig. 58 Exemplo de Linhagem de dados no dbt#
Orquestração#
A documentação conclui as etapas básicas que devem constar de qualquer projeto de transformação de dados em dbt. Vale ressaltar que projetos de ETL raramente são lineares: geralmente passamos por diversas iterações de cada etapa do projeto, desde mapeamento de novas fontes, criação dos modelos, testes e documentação. Depois de validados, ainda precisamos apontar os modelos para um banco de dados em produção que será de fato consultado por uma ferramenta de BI ou outro uso pelo cliente, além de garantir que esse processo todo rode na frequência e horário adequado para os fins do projeto, processo também chamado de Orquestração.
O dbt open-source (também chamado de dbt core) não possui um orquestrador nativo, de modo que a orquestração do projeto precisa ser feita por uma ferramenta externa como o Airflow ou Prefect. Uma outra alternativa é utilizar o serviço do dbt cloud, uma solução SaaS dos criadores do dbt que facilita o deploy de projetos em dbt e que possui um orquestrador incorporado.
Conclusão#
Chegamos ao fim de nosso exemplo prático de transformação de dados com dbt e também de nossa Parte 3: Transformando dados com ELT. Espero que esse conteúdo seja útil para sua jornada de Engenharia de Analytics com o ELT e com o Modern Data Stack.