13.1 O Precursor: ETL
13.1 O Precursor: ETL#
Durante muito tempo (e ainda utilizado em muitas empresas atuais), o processo padrão de de construção de pipelines de dados era o ETL. ETL (do inglês, extract-transform-load) é o processo sistemático de extrair, transformar, limpar e carregar os dados brutos em um banco de dados ou outro local para visualização ou consumo por outra aplicação. Cada letra da sigla significa uma de suas etapas:
Extract: recuperar dados brutos de uma ou mais fontes e salvá-los em um repositório de dados único
Transform: estruturar, enriquecer, limpar e converter dados brutos para um modelo de dados final.
Load: carregar os dados transformados para um data warehouse ou repositório de dados para utilização em uma ferramenta de BI.
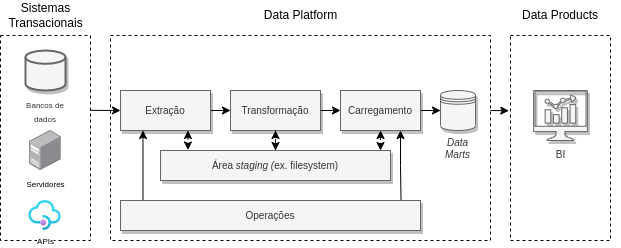
Fig. 45 Exemplo de processo de ETL#
A sigla ETL não apenas lista suas as etapas, mas também representa a ordem em que tradicionalmente essas etapas são realizadas em um projeto. No Modern Data Stack, no entanto, uma outra abordagem é proposta chamada de ELT, em que primeiro os dados brutos são carregados para um Data Warehouse e depois transformados dentro do próprio DW. Para evitar confusões e manter o padrão do MDS, usaremos a sigla ELT para denotar o processo como um todo.