6.4 Git na prática
Contents
6.4 Git na prática#
Agora que entendemos a importância do versionamento de código e os conceitos por trás do Git podemos partir para a prática! Nas próximas seções mostraremos os comandos mais utilizados do Git de forma intrudutória para que você possa começar a entender o processo como um todo. Para a grande maioria das pessoas a experiência com Git é uma mistura de amor e ódio, e somente com a prática você vai se sentir mais confortável em utilizá-lo. Vamos lá?
Como instalar o Git#
O Git pode ser instalado nos principais sistemas operacionais conforme instruções neste link. Para usuários do Linux(debian), é possível instalá-lo através do apt-get (se já não estiver instalado por padrão na sua distribuição):
sudo apt-get install git-all
Atenção!
Para usuários do Windows, é importante verificar se o Git está corretamente adicionado ao PATH, caso contrário você não conseguirá utilizá-lo. Se estiver com dificuldades para instalar o Git no Windows tenta seguir o passo-a-passo neste link.
Antes de começar a utilizar o Git é importante configura nosso usuário para que o Git saiba quem está realizando as alterações no código. Para isso basta roda o seguinte comando no terminal ou no seu cliente Git de escolha (lembre-se de alterar o nome e email para os seus dados:
git config --global user.name "João Silva"
git config --global user.email "seuemail@exemplo.com.br"
Iniciando um projeto#
Para iniciar um repositório git utilizamos o comando git init. Esse comando criará alguns arquivos ocultos de metadados do Git e nos permitirá iniciar nosso versionamento:
cd meu_diretorio_git
git init
Initialized empty Git repository in /home/danielavancini/Projects/meu_diretorio_git/.git/
Também é comum que ao invés de iniciar um novo repositório nós façamos um clone de um repositório já existente. Neste caso, utilizamos o seguinte comando:
git clone https://<servidor_git>/<usuario>/<repositorio>.git
É importante notar que ao clonar um repositório, trazemos para nosso computador não só os arquivos mas a história deles.
Trabalhando com Git#
Como introduzimos na seção anterior, trabalhar com Git consiste em “mover arquivos” entre os três ambientes principais do Git: o diretório de trabalho que contém o estado atual dos arquivos, o índice ou área de preparo que contém os arquivos prontos a serem “salvos” em uma nova imagem e o HEAD que aponta pra última versão “salva” (mais precisamente, do último commit) dos arquivos.
Adicionando alterações ao índice#
Para adicionar alterações no código e/ou novos arquivos ao índice, usamos o comando git add. Ao realizar esse comando, o arquivo entra no estado staged. No entanto, o arquivo só será salvo de fato na história do git ao realizarmos um commit.
git add <nome_do_arquivo>
Para remover um arquivo do índice, ou seja, realizar uma operação inversa do git add, usamos o git reset:
git reset <nome_do_arquivo>
O diagrama abaixo mostra um resumo dos estados dos arquivos e as operações mais comuns:
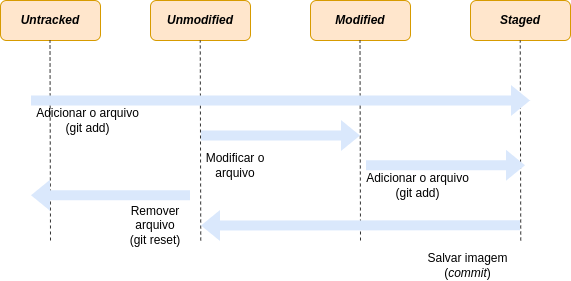
Fig. 21 Adicionando e removendo arquivos do índice#
Realizando um commit#
Quando realizamos um commit, registramos uma imagem de nosso diretório no registro do git. É o equivalente a “salvar” nosso trabalho no vocabulário do Git. Além das alterações nos arquivos, cada commit também possui uma mensagem sobre o que foi feito/alterado e um identificador único que nos permite retornar para essa versão do projeto se necessário:
git commit -m “meu novo commit”
[develop 2c6c86c] meu novo commit
1 file changed, 4 insertions(+), 2 deletions(-)
Para ver a história de commits usamos o comando git log . Esse comando permite visualizar o Hash de cada commit, necessário para identificá-los:
commit 2c6c86c21aa330b60938ae0a792ca60f6fc7b7bc (HEAD -> develop)
Author: Daniel Avancini <danielavancini@indicium.tech>
Date: Fri Oct 28 14:08:43 2022 -0400
meu novo commit
Trabalhando com Branches#
Uma das funcionalidades mais poderosas do Git é a capacidade criar “mundos paralelos” do diretório de trabalho através de branches (ou galhos).
Tecnicamente, uma branch é apenas uma referência para um commit específico. Para saber em qual branch o diretório está, o Git utiliza um ponteiro chamado HEAD.
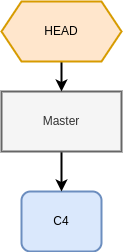
Fig. 22 Ao iniciar, o HEAD aponta para o commit C5 da branch master#
Ao criar uma branch, nós simplesmente criamos uma nova referência para um commit. Para podermos trabalhar nela, precisamos apontar o HEAD para a nova branch através do git checkout:
git checkout -b minha_branch
Switched to a new branch 'minha_branch'
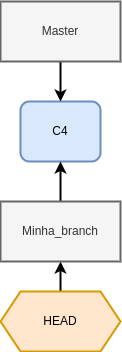
Fig. 23 Quando fazemos o checkout para uma nova branch, mudamos a posição do HEAD para ela#
Novos commits são adicionados na nova branch mas o Git entende a história e o momento que ela divergiu da branch master original:
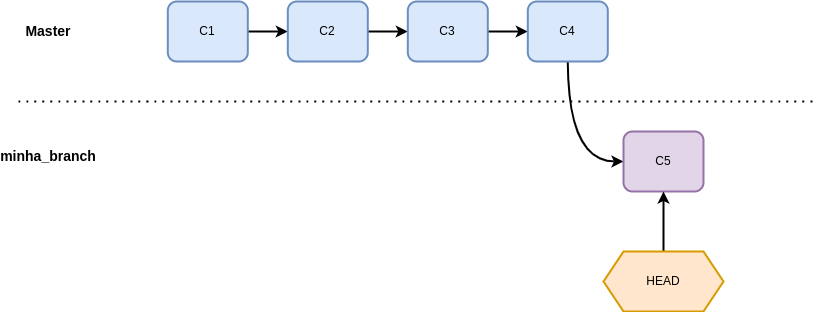
Podemos fazer esse mesmo processo inúmeras vezes e de forma paralela:
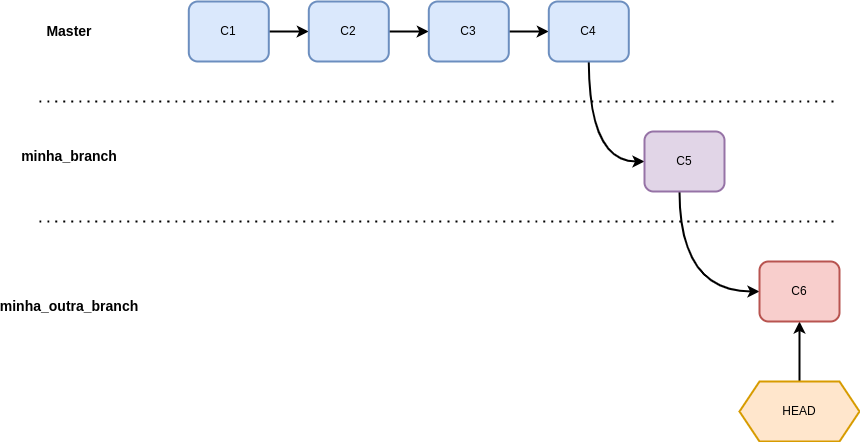
Podemos acessar qualquer branch (ou commit) utilizando o git checkout também.
git checkout master
Switched to branch 'master'
Mas como fazemos para “juntar” diferentes branches? git merge!
O Git merge#
Para consolidar a história de duas branches distintas, utilizamos o comando git merge. Esse comando é uma das funcionalidades mais poderosas do Git, porque ao realizar essa consolidação do trabalho ele também lida com possíveis conflitos entre arquivos.
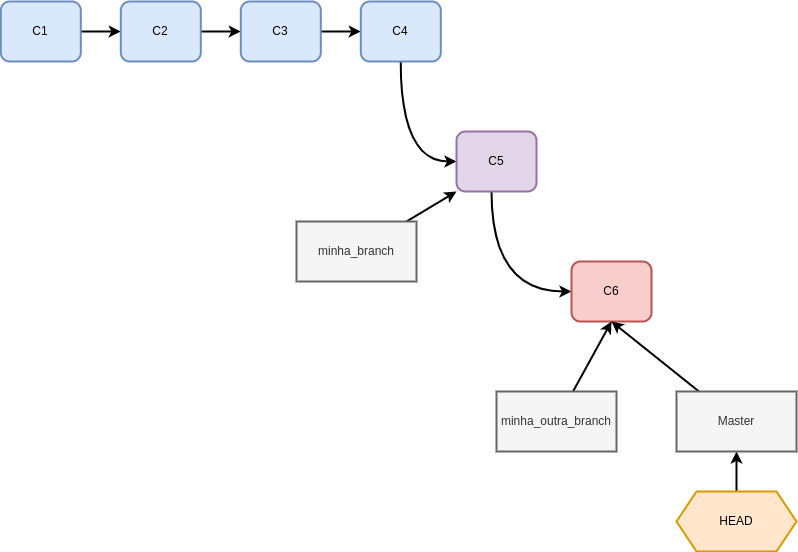
Vamos supor que estamos trabalhando na minha_outra_branch e quiséssemos realizar o merge com a master. Como as histórias foram sequenciais, não deveríamos ter qualquer conflito e o Git apenas aponta uma nova referência da master para o commit C6:
git merge minha_outra_branch
Mas se ao invés de alterações sequenciais, tivéssemos trabalhado de forma paralela na master e na minha_branch? Neste caso o Git precisa encontrar um ponto em comum entre as dias e verificar se há algum conflito. Em caso negativo, uma nova árvore é criada mesclando a história das duas branches :
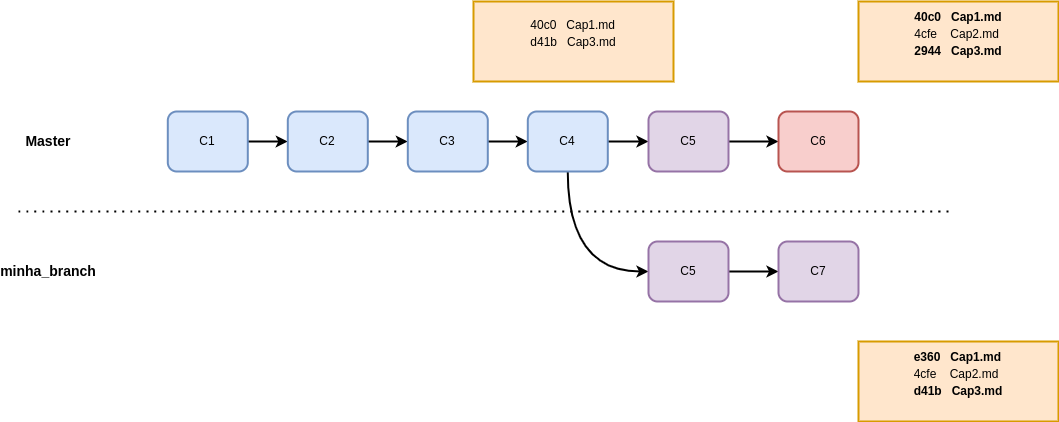
Fig. 24 Ao trabalhar em paralelo, precisamos descobrir qual a raiz comum entre as branches#
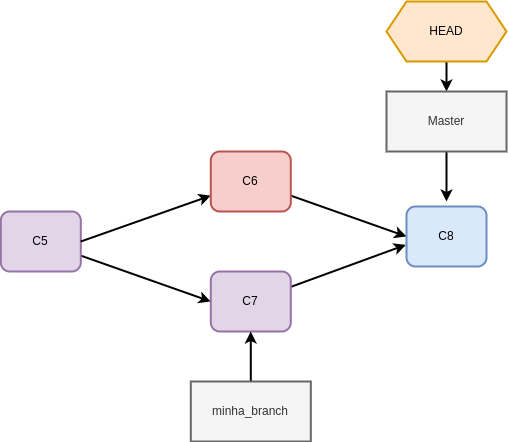
Fig. 25 Se não houver conflito, o Git cria um novo commit para registrar o merge entre as histórias#
Lidando com conflitos#
O que acontece se dois commits alterarem o mesmo arquivo de forma paralela? Neste caso teremos um conflito ao tentar fazer um merge!!
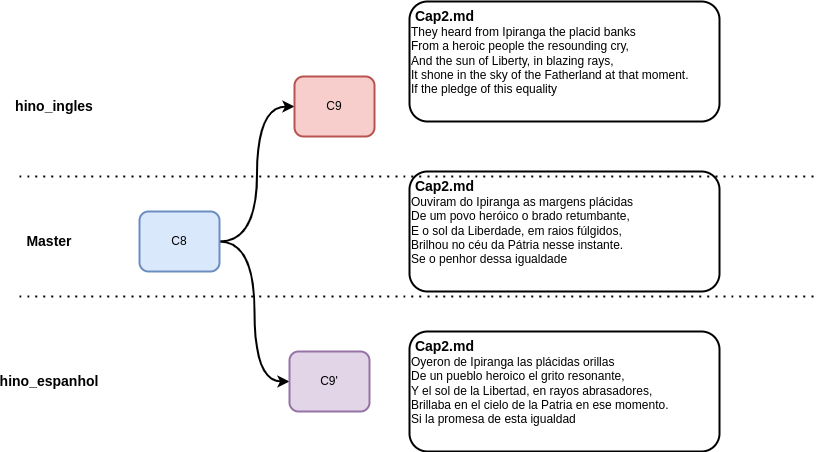
Fig. 26 Neste exemplo, há três versões distintas para o mesmo arquivo. Como conciliar? Qual é a correta?#
Embora o Git consiga identificar um conflito de forma automática, ele não sabe como resolvê-los. Cabe a nós indicar ao Git qual é a versão certa do código que queremos manter:
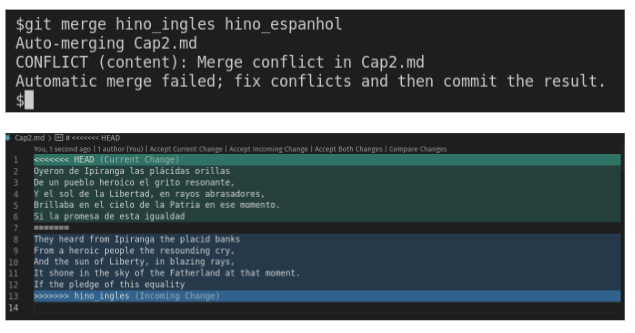
Fig. 27 O Git consegue identificar cada linha de código em conflito#
Para resolvermos um conflito, precisamos alterar os arquivos para conter somente o código correto e realizar um novo commit para salvar as mudanças.
Importante!
Quando há muitos conflitos na hora de realizar um merge pode ser difícil e trabalhoso resolvê-los manualmente. É por isso que a boa prática de Git recomenda realizar commits pequenos continuamente e utilizar ferramentas de CI/CD pra facilitar a resolução de conflitos.
Lidando com repositórios remotos#
Na última seção de nosso tutorial de Git na prática vamos falar de repositórios remotos, que são os servidores que centralizam o armazenamento e facilitam o trabalho colaborativo entre equipes ou mesmo publicamente.
O git permite trabalhar com diferentes repositórios “remotos” (isto é, na internet, um servidor local ou mesmo em nosso próprio pc). O comando git remote é utilizado para interagir com esses repositórios. Usamos o comando git remote -v para listar os remotes com seus urls.
$ git remote -v
origin git@github.com:dpavancini/eng-de-analytics-livro.git (fetch)
origin git@github.com:dpavancini/eng-de-analytics-livro.git (push)
Você sabia?
Não existe nada de especial no remote “origin”. É apenas um padrão do git. Poderíamos usar qualquer outro nome!
Sincronizando com o remoto#
Para sincronizar uma branch local com o repositório remoto usamos git push. Você precisa dizer qual branch quer enviar para o remoto e também ter permissões de escrita. Além disso, se outras pessoas tiverem adicionado commits na mesma branch, você precisará integrá-los antes.
git push <remote> <branch>
Quando queremos trazer todas as mudanças remotas para o repo local, usamos git fetch. Esse comando atualiza nosso repositório local com as novas referência do remoto, mas não atualiza nossa branch automaticamente (não realiza o merge).
git fetch
Muitas vezes não queremos apenas atualizar as referências, mas também diretamente trazer mudanças no código do remoto. Para isso, podemos usar o git pull. Esse comando realiza o git fetch e git merge.
git pull <remote> <branch>
Finalizamos nosso tutorial com o primeiro comando remoto que apresentamos, o git clone. O git clone é na verdade uma série de operações em uma:
Cria uma nova pasta local
Adiciona um remoto “origin” com a URL usada no clone
Cria uma branch local a partir da branch ativa do remoto
Realiza um git fetch
Realiza um git pull da branch ativa (em geral, master)
Trabalhar com remotos no Git é muito semelhante ao desenvolvimento local e vai utilizar os comando que você já conhece como o git checkout, git merge etc. Agora você tem uma visão introdutória de versionalmento de código com Git e já conseguirá aplicar as boas práticas de programação necessárias para a Engenharia de Analytics. Se ainda tem dúvidas utilize os materiais adicionais listados na próxima seção.