7.2 Arquitetura de Referência
Contents
7.2 Arquitetura de Referência#
O framework de referência do MDS serve para exemplificar as funções de cada módulo do MDS de modo a auxiliar o entendimento e construção de arquiteturas derivadas. É importante notar que as funções detalhadas abaixo podem ser executadas por uma única ferramenta ou serem parte de um conjunto de funcionalidades (ex. um Data Warehouse Cloud como o Google BigQuery inclui Armazenamento, Processamento (VMs), APIs, Controle de Acesso e Motor de BigData em uma única ferramenta).
Componentes#
Nesta seção apresentamos rapidamente o objetivo de cada componente da arquitetura de referência do MDS e exemplos de ferramenta que o implementa. Para uma outra lista de ferramentas veja esse link.
Os componentes mais comuns (Core) em implemetações de MDS são apresentados em vermelho no diagrama ao final desta seção. Já os componentes que aparecem em projetos sob demanda estão em amarelo.
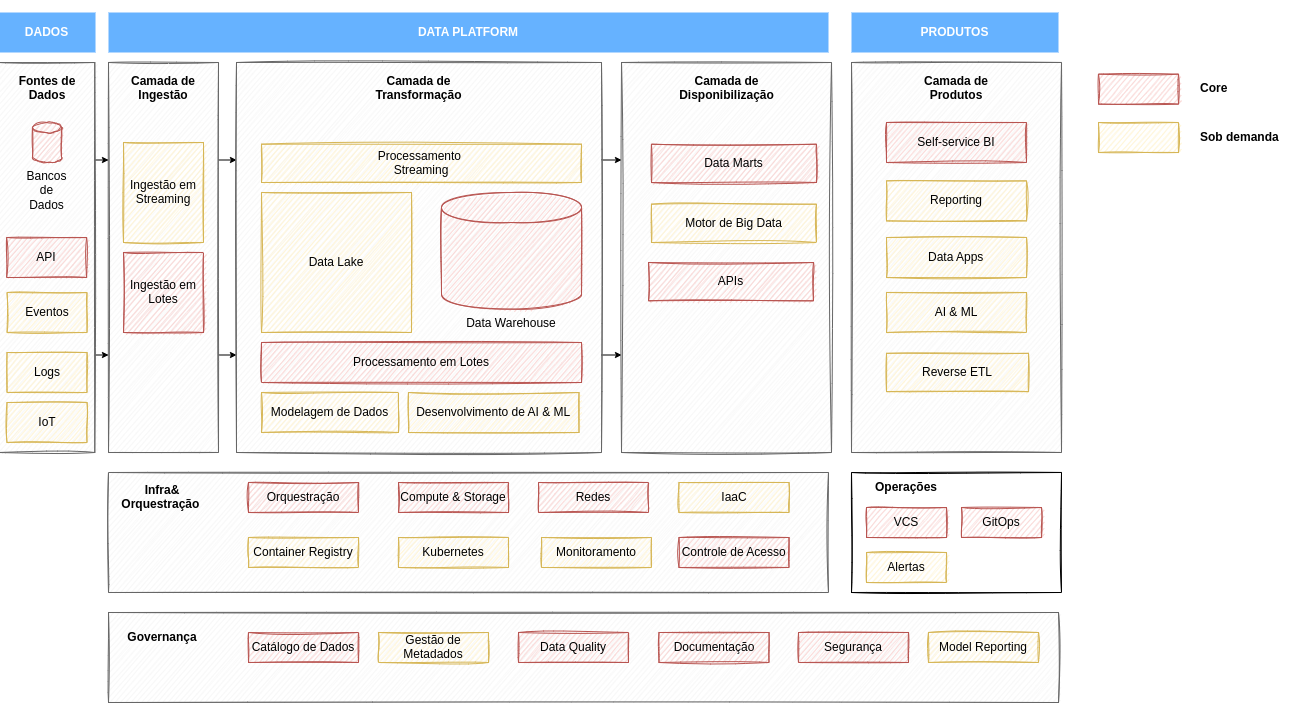
Fig. 28 Arquitetura de referência do Modern Data Stack#
Fontes de Dados#
As fontes de dados geralmente são determinadas pela infraestrutura do cliente e são premissas da arquitetura. No entanto, em alguns casos a implementação pode envolver a configuração ou adequação de alguma fonte de dados também.
Core Os componentes de fontes de dados mais comuns são:
Banco de Dados: são as fontes de dados mais comuns em sistemas legados e parte essencial da grande maioria dos softwares empresariais. Podem ser divididos em bancos de dados relacionais (SQL) ou não-relacionais (NoSQL). Em geral são acessados via conexões do tipo JDBC ou ODBC. Em alguns projetos pode ser necessário realizar uma cópia completa do banco de dados, procedimento chamado de clonagem.
API: APIs, ou mais precisamente REST APIs, são o protocolo de comunicação entre sistemas mais utilizado atualmente. Quando acessamos uma API, o sistema original é protegido por essa nova camada de comunicação, de modo que não temos acesso ao banco de dados original. Neste tipo de integração, é possível que parte dos dados necessários não esteja disponível na API e precise ser desenvolvido pelo cliente.
Sob Demanda Os componentes de fontes de dados menos usuais são:
Eventos: fontes de eventos coletam ações em sistemas em tempo-real, por exemplo, cliques em um website ou utilização de um app. Algumas fontes de eventos são configuradas por sistemas SaaS (como Google Analytics 4), outras podem ser desenvolvidas de forma personalizada para cada projeto (ex. Snowplow) ou de forma híbrida (ex. CDP).
Logs: são fontes de dados que utilizam os logs de aplicações. Podem ser coletadas em tempo-real ou não.
IoT: são fontes de dados de equipamentos físicos como máquinas, sensores etc. Em geral, processadas em tempo-real.
Camada de Ingestão#
A camada de ingestão inclui componentes responsáveis por extrair dados das fontes de dados e carregar em um outro ambiente (como um data lake e data warehouse). Essa camada também é conhecida pelos termos Extract-load dentro do MDS.
Core Os componentes da camada de ingestão mais comuns são:
Ingestão em lotes: é o processo de extrair um grande volume de dados de uma ou mais fontes em um intervalo específico (ex. a cada 24 horas) ou cronograma (ex. todo dia às 2:00AM). Neste tipo de integração, a plataforma de dados busca os dados na fonte de forma ativa.
Sob Demanda Os componentes da camada de ingestão menos usuais são:
Ingestão em streaming: é o processo de ingestão de dados em tempo-real, necessário para fontes de dados de Eventos, IoT e Logs em geral. Neste tipo de ingestão, a plataforma de dados recebe os dados de forma passiva através de um sistema que “escuta” eventos (ex. Apache Kafka ou Google PubSub).
Camada de Transformação#
A camada de transformação) é responsável por processar e armazenar os dados extraídos as fontes de dados originais até seu formato final para consumo pelos produtos de dados.
Core Os componentes da camada de ingestão mais comuns são:
Data Warehouse: o data warehouse é um banco de dados analítico capaz de armazenar, processar e disponibilizar enorme volume de dados para a tomada de decisão. Ele pode ser desenvolvido de uma forma que abstrai suas partes mais técnicas e disponibiliza somente a interface necessária para construção dos modelos (isto é, tabelas) como é o caso dos Cloud Data Warehouses (Google Big Query, Amazon Redshift, Azure Synapse e Snowflake) ou ter uma arquitetura mais flexível que também é chamada de Data Lakehouse. Na visão do MDS, o Data Warehouse não serve apenas como um banco de dados bruto mas precisa ser modelado para atender aos requisitos de cada cliente, tarefa que fica a cargo da Engenharia de Analytics.
Processamento em Lotes: o componente de processamento em lotes é responsável por executar a transformação de dados brutos em dados modelados. Salvo exceções, o processamento é realizado dentro do Data Warehouse através da arquitetura ELT. Em alguns projetos esse processamento pode ser separado do armazenament, como no caso da construção de Data Lakehouses.
Modelagem de Dados: para realizar a modelagem de dados, isto é, a aplicação de regras de negócio, transformações, construção de tabelas etc. utilizamos a ferramenta dbt dentro do MDS. Essa ferramenta não processa dados diretamente mas envia instruções (em SQL) para o componente de processamento em lotes da plataforma.
Sob Demanda Os componentes da camada de ingestão menos usuais são:
Data Lake: um data lake é um repositório de dados com armazenamento virtualmente infinito que permite guardar qualquer tipo de arquivo digital. Ele pode ou não estar presente no MDS conforme a necessidade e criticidade do projeto.
Processamento Streaming: projetos que possuem fontes de dados em tempo-real necessitam de um componente de processamento de dados em streaming, que consegue processar os dados à medida que chegam na plataforma de dados.
Desenvolvimento de AI&ML: o desenvolvimento de modelos de AI & ML só é previsto em projetos com uma plataforma de dados mais desenvolvida, devido à visão de tratar modelos como software. Para o desenvolvimento de modelos é prevista a utilização de Notebook gerenciados na nuvem (Amazon SageMaker, Google Vertex, etc) ou através de um PaaS como a Databricks. O desenvolvimento e deploy dos modelos deve seguir um processo de MLOps bem estruturado e para isso recomendamos o uso do framework Kedro.
Camada de Disponibilização#
Também chamada de serving layer, essa camada é em geral invisível e parte das ferramentas utilizadas pelo MDS. No entanto, em projetos mais complexos pode ser necessário separar componentes que disponibilizam dados e serviços dos componentes que os constroem.
Core Os componentes da camada de Disponibilização mais comuns são:
Data Marts: os data marts disponibilizam as tabelas finais do processo de ELT de forma estruturada, documentada e otimizada para consulta pelos produtos de dados e analistas. Em geral, são disponibilizados pelo próprio Data Warehouse mas em alguns casos pode ser necessário a utilização de uma camada semântica para acelerar consultas.
APIs: APIs são interfaces de comunicação entre os produtos de dados e ambientes externos com a plataforma de dados e incluem interfaces padronizadas (como conexões JDBC com o DW) e APIs gateways que podem ser necessários por questões de desempenho e segurança de cada projeto.
Sob Demanda Os componentes da camada de Disponibilização menos usuais são:
Motor de Big Data: motor de big data (ou Big Data Query Engines) permitem consultar grandes volumes de dados armazenados no Data Lake sem a necessidade de um Data Warehouse. Podem existir em projetos maiores onde há a necessidade desse tipo de acesso direto utilizando ferramentas como o Athena, Presto e Dremio.
Camada de Produtos#
A camada de Produtos é a camada que expõe produtos de dados para consumidores externos à plataforma de dados como analistas de dados, outras aplicações etc. Na arquitetura MDS os produtos de dados devem necessariamente ser construídos em cima de uma plataforma de dados que exponha os componentes estruturais necessários para sua construção.
Core Os componentes da camada de Produtos mais comuns são:
Self-service BI: o self-service BI é uma ferramenta de suporte à tomada de decisão que permite construir visualizações de dados e gerar insights a partir dos dados. É uma ferramenta essencial em qualquer infraestrutura de dados para analytics e incluir ferramentas como Microsoft PowerBI, Tableau, Metabase, Mode, Looker etc.
Sob Demanda Os componentes da camada de Produtos menos usuais são:
Reporting: inclui ferramentas que permitem a construção e automação do envio de relatórios.
Data Apps: são apps (web ou mobile) que permitem interagir com os dados da plataforma ou modelos de AI.
Reverse ETL: o reverse ETL é um componente que permite entregar dados da plataforma de dados via API para as fontes de dados do cliente. Por exemplo, podemos entregar uma classificação de clientes (ex.RFV) para o CRM para otimizar o processo de gestão de carteira.
AI & ML: são componentes que permitem rodar novos dados em um modelo de machine learning para calcular uma previsão.
Infra & Orquestração#
Esta camada disponibiliza recursos para o funcionamento da plataforma de dados. Em versões do MDS mais simples, seus componentes estão em geral embutidos em ferramentas gerenciadas e não são diretamente acessáveis.
Core Os componentes da camada de Infra & Orquestração mais comuns são:
Orquestração: componente responsável por orquestrar a execução dos demais componentes da plataforma. Pode ser uma ferramenta dedicada (ex. Apache Airflow) ou parte de outros componentes (ex. execução por intervalos ou periódica).
Compute & Storage: inclui componentes mais próximos do bare metal ou virtualizações de recursos de computação (ex. Máquinas Virtuais EC2) e armazenamento (ex. HDs). Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Redes: componentes que fornecem recursos de comunicação de rede como IPs estáticos e dinâmicos, grupos de segurança, subredes. Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Controle de Acesso: componentes que permitem gerenciar o acesso à plataforma de dados (ex. IAM).
Sob Demanda Os componentes da camada de Infra & Orquestração menos usuais são:
Monitoramento: componentes que monitoram os recursos da plataforma como consumo de dados, faturamento, etc.
Container Registry: componentes que realizam o registro de Docker Containers ou Kubernetes
IaC: componentes de Infrastructure as code que permitem modularizar e gerenciar infraestrutura em nuvem (ex. Terraform).
Kubernetes: é um sistema de orquestração de contêineres open-source que automatiza a implantação, o dimensionamento e a gestão de aplicações em contêineres.
Operações#
Esta camada é responsável pela operação do desenvolvimento de software como respositório de código, pipelines de CI/CD e alertas.
Core Os componentes da camada de Operações mais comuns são:
VCS: esse componente é responsável pelo controle de versão de código como git, bitbucket e gitlab. É um componente core do MDS pois um dos princípios dessa arquitetura é o de tratar Analytics as Code.
Sob Demanda Os componentes da camada de ingestão menos usuais são:
CI/CD: componentes responsáveis por CI/CD são utilizados para garantir boas práticas de DevOps. Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Alertas: componentes de alertas verificam o sucesso das integrações e outros avisos. Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Governança#
Core Os componentes da camada de Governança mais comuns são:
Documentação: componentes responsáveis por disponilizar e manter atualizada a documentação de códigos, processos etc. da Plataforma de Dados. Pode ser embutido em outros componentes (ex. dbt docs) ou uma ferramenta específica (ex. Wiki ou Confluence).
Segurança: componentes responsáveis por garantir a segurança da plataforma e monitorar uso de dados pessoais, sensíveis etc. Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Data Quality: componentes responsáveis por garantir a qualidade dos dados da plataforma. Pode ser parte de outro componente (ex. testes no dbt) ou uma ferramenta específica (ex. GreatExpectations).
Catálogo de Dados: componente responsável por catalogar e documentar os dados disponíveis na plataforma de dados, assim como apresentar o data lineage de criação desses dados. Pode ser parte de outro componente (ex. dbt docs) ou uma ferramenta específica (ex. Openmetadata).
Sob Demanda Os componentes da camada de Governança menos usuais são:
Gestão de Metadados: componente responsável por gerenciar os metadados dos demais componentes da plataforma (Ex. Backstage). Em geral, em arquiteturas MDS menos complexas esses recursos não são acessáveis diretamente.
Model Reporting: componente responsável por monitorar e reportar resultados de modelos de Machine Learning (ex. MLFlow.