4.4 Trabalhando com índices
4.4 Trabalhando com índices#
Para melhorar o desempenho das consultas, os bancos de dados geralmente possuem uma estrutura de dados adicional chamada de índice. Os índices existem para evitar escanear toda uma tabela sempre que um registro precisar ser consultado e podem ser criados a partir de uma ou mais colunas de uma tabela. Como analytics engineer você vai cedo ou tarde passar por índices na hora de consultar dados de uma tabela ou para melhorar o desempenho de uma consulta que está demorando mais que o desejado.
Para entender melhor porque os índices são necessários é interessante detalhar um pouco melhor como os bancos de dados armazenam os dados de fato no disco do computador (o HD). Na figura 4.1 vimos que os SGBDs separam a camada de armazenamento da camada de consulta. Sempre que uma consulta é enviada para o motor do banco de dados, ele precisa realizar uma série de operações para encontrar onde esses dados estão de fato guardados na memória ou disco do computador e retornar esses dados para o usuário ou aplicação que fez a requisição. Como bancos de dados precisam armazenar grandes volumes de dados, geralmente não é possível utilizar um único arquivo como é feito em uma planilha eletrônica. Na verdade, as tabelas de um banco de dados são divididas em páginas (ou blocos), a unidade mínima que o banco de dados consegue ler e escrever para um arquivo em disco e que armazenam apenas uma parte das linhas e colunas da tabela, além de algumas estatísticas como o valor máximo e mínimo que vão facilitar a consulta futuramente. Agora, vamos supor que você queira consultar um pedido de uma tabela no banco de dados do ERP da sua empresa. Como o banco de dados não tem como saber de antemão onde esse pedido está entre as milhões de linhas da tabela de vendas, ele vai precisar escanear toda a tabela até encontrar esse pedido. Pior, ele precisa escanear cada página dessa tabela, gastando mais tempo de processador e de leitura de dados para ler cada página do disco em memória, procurar o pedido e retornar os dados processados.
É claro que deveria existir alguma forma de otimizar esse processo de consulta, e para isso os bancos de dados utilizam uma estrutura chamada índice, que da mesma forma que um índice em um livro, dá atalhos para a localização de cada registro indexado no banco de dados. O processo de criação desse índice exige que uma nova estrutura de dados seja criada, mapeando cada valor do índice à sua localização física em disco (sua página). Por outro lado, como a leitura de dados utilizando índices é muito mais rápida, é comum que os bancos de dados utilizem índices para as chaves primárias ou outras colunas que são consultadas com frequência. A figura 4.3 apresenta uma simplificação de como esse processo ocorre em uma tabela e como a criação de um índice facilita a consulta pelo banco de dados.
Fig. 7 Consultas e índices em um banco relacional.#
Embora os índices sejam essenciais para obter consultas rapidamente em bancos transacionais, seu uso é muito mais limitado para consultas analíticas. Isso ocorre porque a consulta analítica não se preocupa em obter os dados de um pedido específico ou um cliente específico, mas sim obter agregados sobre um grande número de linhas. A consulta analítica traz consigo algumas dificuldades para a estrutura de dados tradicional dos bancos de dados. A primeira dificuldade é que é comum utilizar colunas não indexadas para realizar filtros, juntar tabelas ou calcular agregados. O analista raramente sabe previamente todas as possíveis consultas que irá realizar e que poderiam ser otimizadas com a criação de índices ou outras estruturas.
A segunda dificuldade é que os bancos de dados tradicionais armazenam os dados fisicamente nas páginas como linhas, o que facilita a consulta pelas chaves primárias indexadas das tabelas. No entanto, é raro que uma consulta analítica precise retornar muitas colunas de um único registro. Pelo contrário, o normal em consultas agregadas é realizar contagem ou somas de muitas linhas de uma ou poucas colunas de uma tabela por vez. Isso faz com que o banco de dados tenha que retornar um volume de dados do disco muito maior que o necessário para cada consulta, aumentando a necessidade de CPU e memória e muitas vezes impossibilitando o uso de bancos de dados tradicionais para projetos analíticos. Para contornar essa dificuldade, bancos de dados colunares foram desenvolvidos que armazenam as colunas de forma sequencial e utilizam de estruturas como os sort-maps para realizar operações rapidamente em volumes de dados que podem chegar a petabytes.

Fig. 8 Em bancos de dados tradicionais, os blocos armazenam linhas da tabela#
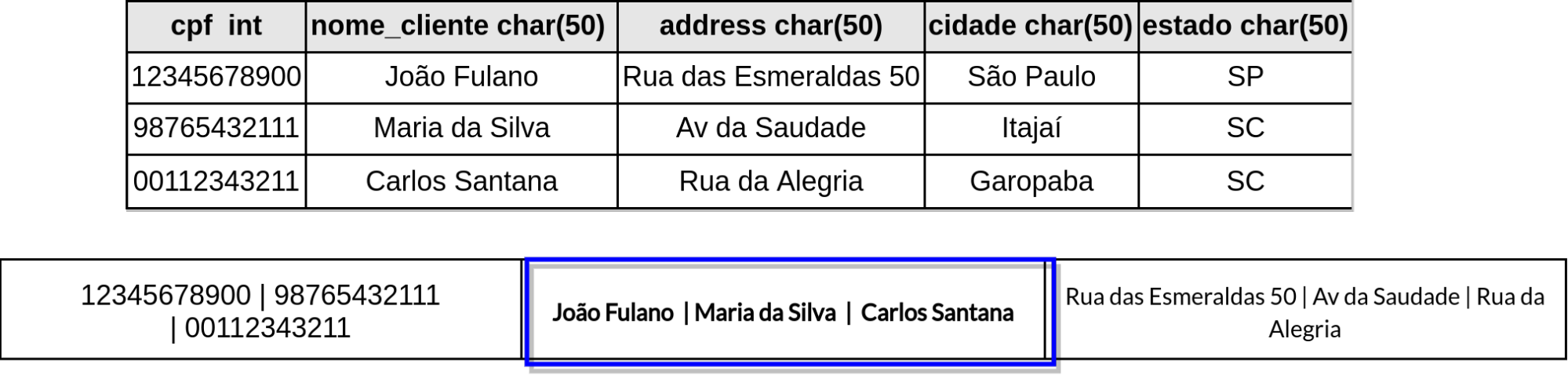
Fig. 9 Bancos colunares armazenam colunas de forma sequencial#
Note que no banco de dados tradicional, cada página armazena os dados de uma linha. Para realizar uma contagem de nomes de clientes distintos, por exemplo, é necessário retornar todos os dados de cada página como CPF, cidade, etc que serão descartados. Por outro lado, no exemplo da figura 4.5 os dados de nome de clientes estão todos armazenados no mesmo bloco e podem ser consultados sem uso de memória adicional.
Como vimos acima, bancos de dados possuem uma estrutura formal e regras pré-definidas para garantir que as entidades de negócio sejam representadas de forma fiel e consistente nos sistemas que fazem uso desses bancos. Deste modo, o desenvolvimento dos bancos de dados precisa seguir alguns processos e boas práticas que facilitem o seguimento dessas regras. Na próxima seção é apresentado um desses processos que é parte essencial da rotina do analytics engineer, a modelagem de dados.